

Celery
基础
Celery 架构
Celery 由以下三部分构成:消息中间件(Broker)、任务执行单元(Worker)、结果存储(Backend)。
场景:
- 异步任务:一些耗时的操作可以交给 Celery 异步执行,例如视频转码、邮件发送、消息推送等。
- 定时任务:例如定时推送消息、定时爬取数据、定时统计数据等。
组件:
- Producer:生产者,专门用来生产任务(task)。
- Celery Beat:任务调度器,周期性地将到期需要执行的任务发送给消息队列。
- Broker:任务队列,用于存放生产者和调度器生产的任务。
- Worker:任务的执行单元,会将任务从队列中顺序取出并执行。
- Backend:用于在任务结束之后保存状态信息和结果,以便查询。
graph TD
A[Task Client] -->|提交任务| B[Broker]
C[Task Client] -->|提交任务| B
D[Task Client] -->|提交任务| B
B --> E[Worker]
B --> F[Worker]
B --> G[Worker]
E -->|存储结果| H[Backend]
F -->|存储结果| H
G -->|存储结果| H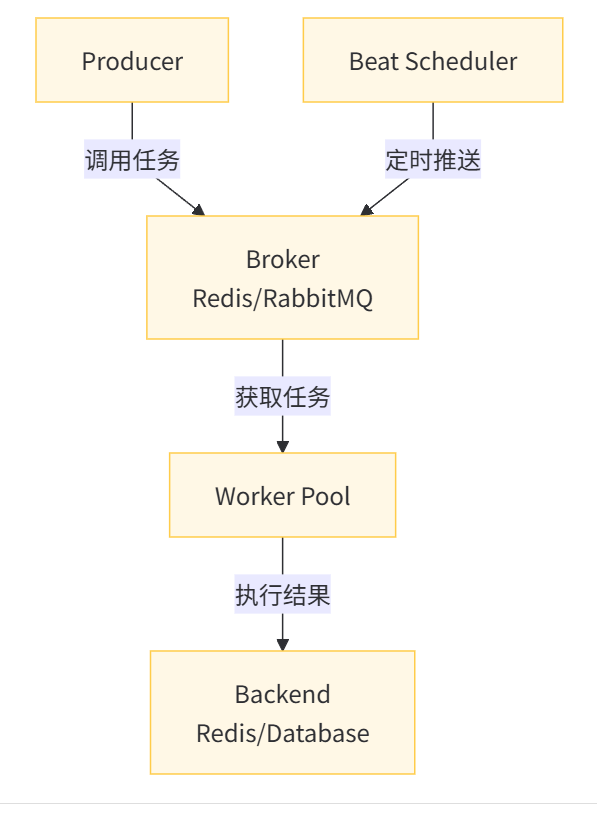
工作原理
- 调度器初始化:
- 读取配置的周期性任务(在 beat_schedule 中定义)
- 加载调度器(默认是 celery.beat.PersistentScheduler)
- 调度循环:
- Beat 进程持续运行一个无限循环
- 每次迭代检查当前时间是否有任务需要执行
- 使用最小堆数据结构高效管理任务执行时间
- 任务发布:
- 当任务执行时间到达时,Beat 将任务消息发送到消息队列
- 消息包含任务名称、参数和执行时间等信息
- 任务执行:
- Worker 从队列中获取任务并执行
- 执行结果可存储在结果后端(如 Redis、数据库等)
- 持久化:
- 默认情况下,Beat 会将调度状态存储在本地文件(celerybeat-schedule)
- 确保重启后不会重复执行已执行的任务
调度算法
基于时间的优先级队列:
- 使用最小堆来管理任务
- 堆顶总是下一个要执行的任务
间隔计算:
- 对于固定间隔的任务(如每 5 分钟),计算下一次执行时间
- 对于 crontab 式任务,使用类似 cron 的算法计算下次执行时间
from celery import Celery
from celery.schedules import crontab
app = Celery('tasks', broker='pyamqp://guest@localhost//')
app.conf.beat_schedule = {
'add-every-30-seconds': {
'task': 'tasks.add',
'schedule': 30.0, # 每30秒
'args': (16, 16)
},
'every-monday-morning': {
'task': 'tasks.send_email',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': ('recipient@example.com',),
},
}Task 对象
通过对一个函数使用 @app.task 即可将其变成一个任务工厂,而这个任务工厂就是一个 Task 实例对象。在使用 @app.task 的时候,可以加上很多的参数:
- name:默认的任务名是一个 uuid,可以通过 name 参数指定任务名。
- bind:一个 bool 值,表示是否和任务工厂进行绑定。
- base:定义任务的基类,用于定义回调函数。
- default_retry_delay:设置该任务重试的延迟机制。
- serializer:指定序列化的方法。
自定义任务流
有时候我们也可以将执行的多个任务,划分到一个组中:
from celery import group
t1 = add.signature(args=(2, 3))
t2 = sub.signature(args=(2, 3))
t3 = mul.signature(args=(2, 3))
t4 = div.signature(args=(4, 2))
gp = group(t1, t2, t3, t4)
res = gp()
print("组结果:", res.get())
定时任务
# celery_demo/tasks/period_task1.py
from celery.schedules import crontab
from app import app
@app.on_after_configure.connect
def period_task(sender, **kwargs):
sender.add_periodic_task(10.0, task1.s(), name="每10秒执行一次")
sender.add_periodic_task(15.0, task2.s("task2"), name="每15秒执行一次")
sender.add_periodic_task(20.0, task3.s(), name="每20秒执行一次")
sender.add_periodic_task(
crontab(hour=18, minute=5, day_of_week=0),
task4.s("task4"),
name="每个星期天的18:05运行一次"
)shared_task
shared_task 是 Celery 提供的一个装饰器,用于创建可以在多个应用中共享的任务。
它允许任务在不同的 Celery 应用实例中被注册和调用,而无需显式地将任务绑定到某个特定的 Celery 应用。
使用场景
在大型项目中,多个 Celery 应用可能需要共享一些通用任务,如日志记录、邮件发送等。
shared_task 可以方便地实现这些任务的共享,避免重复定义。
from celery import shared_task
@shared_task
def add(x, y):
return x + y踩坑
入列数据而不是引用
- 问题:在任务参数中直接使用数据库中的数据(如用户的电子邮件地址),而不是数据库中的唯一标识(如用户ID),可能导致数据过时。
- 解决方案:使用数据库中的唯一标识符(如ID),而不是实际数据。这样可以确保在任务执行时,通过标识符获取的数据是最新的。
错误:
@app.task
def send_welcome_email_task(user):
# 直接使用User实例可能导致问题
send_email(user.email, "Welcome!")正确:
@app.task
def send_welcome_email_task(user_id):
user = User.objects.get(id=user_id)
send_email(user.email, "Welcome!")在数据库事务中入列任务
- 问题:如果在数据库事务中入列任务,任务可能会在事务提交之前执行,导致任务访问不到新创建的数据,引发异常。
- 解决方案:使用Django的transaction.on_commit来在事务提交后入列任务。这样可以确保任务在所有相关数据都已提交到数据库后再执行。
from django.db import transaction
@transaction.commit_manually
def create_user(request):
user = User.objects.create(name=request.POST['name'], email=request.POST['email'])
try:
send_welcome_email_task.delay(user.id)
transaction.commit()
except Exception as e:
transaction.rollback()
raise e指定countdown或eta
- 问题:使用eta和countdown参数可能导致Celery工作进程使用大量内存保存延迟任务,影响性能。
- 解决方案:避免使用长时间延迟的任务。如果需要延迟任务,可以考虑向模型实例中添加一个字段来指定执行时间,然后使用定期任务来即时入列。
ACKS行为
- 问题:Celery默认立即确认任务,可能导致非幂等任务在失败时不被重试。
- 解决方案:在Celery配置中设置acks_late = True,使得任务在成功完成后才进行确认。这样可以确保在任务执行过程中出现问题时,任务可以被重试。
也可以 app.conf.task_acks_late = True
不重试漏掉的任务
- 问题:任务可能会因为各种原因(如数据库服务器崩溃)而失败,导致任务丢失。
- 解决方案:使用定期的“清理器任务”来扫描并重试漏掉的任务。这样可以确保因临时问题而失败的任务有机会被重新执行。
不兼容更改任务签名
- 问题:更改任务函数签名(如添加或删除参数)可能导致已入列的任务执行失败。
- 解决方案:像处理数据库迁移一样处理任务函数签名的更改。添加新参数时先给默认值,删除参数或任务时先更新调用位置。这样可以确保新旧版本的兼容性。
任务重试-幂等性
使用Celery的重试机制可能导致任务重复执行,如发送重复邮件。 解决方案:实现幂等性任务,确保任务逻辑只执行一次。
@app.task
def send_welcome_email_task(user_id):
user = User.objects.select_for_update().get(id=user_id)
if not user.is_welcome_email_sent:
send_email(user.email, "Welcome!")
user.is_welcome_email_sent = True
user.save()Celery 不用root启动
使用普通用户运行
# 创建专用用户(如 `celeryuser`)
sudo useradd -m -s /bin/bash celeryuser
sudo passwd celeryuser # 设置密码(可选)
# 切换用户后启动 Celery
su - celeryuser
celery -A proj worker --loglevel=INFO使用 Supervisor/systemd 管理(推荐)
# Supervisor 配置示例(/etc/supervisor/conf.d/celery.conf)
[program:celery]
command=celery -A proj worker --loglevel=INFO
user=celeryuser # 指定普通用户
directory=/path/to/project
autostart=true
autorestart=true使用不同的队列
当有很多任务需要执行时,不要只使用默认的队列,这样会相互影响,拖慢任务执行,导致重要任务不能被快速执行。可以设置不同的队列来优化任务执行:
CELERY_QUEUES = {
'default': {},
'high_priority': {'queue': 'high_priority'},
'low_priority': {'queue': 'low_priority'},
}
CELERY_ROUTES = {
'myapp.tasks.high_priority_task': {'queue': 'high_priority'},
'myapp.tasks.low_priority_task': {'queue': 'low_priority'},
}
多个 workers 执行不同的任务
在同一台机器上,对于优先级不同的任务最好启动不同的 worker 去执行,
例如把实时任务和定时任务分开,把执行频率高的任务和执行频率低的任务分开,这样有利于保证高优先级的任务可以得到更多的系统资源。
$ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker1.%h
$ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker2.%h
$ celery -A proj worker --loglevel=INFO --concurrency=10 -n worker3.%h是否需要关注任务执行状态
这个要视具体的业务场景来看,如果对结果不关心,或者任务的执行本身会对数据产生影响,
通过对数据的判断可以知道执行的结果,那就不需要返回 Celery 任务的退出状态,可以设置:
@app.task(ignore_result=True)
def mytask(…):
something()Celery 内存泄漏
主要原因包括:
- Python 代码未正确释放资源(如未关闭文件、数据库连接、缓存等)。
- 第三方库(如数据库驱动、科学计算库)存在内存泄漏。
- Celery 自身或任务代码中的对象持续累积(如全局变量、缓存未清理)。
限制 Worker 的最大任务数(强制重启)
通过 CELERYD_MAX_TASKS_PER_CHILD 设置,让每个 Worker 在执行一定数量的任务后自动重启,释放内存:
# celeryconfig.py 或 settings.py
CELERYD_MAX_TASKS_PER_CHILD = 100 # 每个 Worker 执行 100 个任务后重启使用 --max-memory-per-child 限制内存(Celery 5.0+)
celery -A proj worker --max-memory-per-child 300000 # 单位 KB(300MB)
检查并修复任务代码的内存泄漏
# 使用 tracemalloc 跟踪内存分配
import tracemalloc
def task_leak_detection():
tracemalloc.start()
# ... 任务代码 ...
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
for stat in top_stats[:10]: # 打印内存占用最高的 10 个位置
print(stat)# 使用 memory_profiler 分析任务内存
from memory_profiler import profile
@profile
def my_task():
# ... 任务代码 ...celery -A proj worker --loglevel=INFO --pool=solo # SoloPool 适用于 memory_profiler